Self Maintenance - Detailed Configuration
All the discoveries, rules, and monitors from the OpsMgr Self Maintenance management packs are disabled by default. This is to ensure OpsMgr administrators only turn on the workflows that are required for the OpsMgr environments they support and configure the required parameters for workflows to suit the environment.
The agent tasks from the management packs are enabled by default.
An unsealed override management pack is provided for each version of the OpsMgr Self Maintenance MP. OpsMgr administrators can use provided unsealed override MP for customization or they can also create their own override MPs for this purpose.
Detailed Configuration Steps
Balancing OpsMgr Agents within a resource pool
Workflow Name: OpsMgr Self Maintenance Balance Agents Within Resource Pool Rule
It is very common that OpsMgr agents are installed using deployment tools such as System Center Configuration Manager or it is built-in as part of the SOE build. OpsMgr administrators rarely have to push agents out via the Discovery method using OpsMgr operational console.
When OpsMgr agents are installed using deployment tools, the primary management server’s FQDN which the agent reports to is specified as part of the installation command line. As a result, when the agents are installed using this method, all agents will end up reporting to a single management server.
In a large environment, where the OpsMgr management group contains multiple management servers for agent management, OpsMgr administrators often have to manually balance agents across multiple management servers.
These workflows serve this purpose by rule scripts on a schedule and automatically balance agents across management servers.
This rule is targeting the “All Management Servers Resource Pool”. It balances the agents among all management servers within a given resource pool. The following parameters can be configured using overrides:
IntervalHours: How often (in hours) does this rule run.
ResourcePoolName: Resource Pool Name
MaxAgentsToMove: Maximum number of agents to be moved at a time.
SyncTime: Optional, what time does the rule run.
TimeoutSeconds: Timeout in seconds for the PowerShell script inside the rule.
An information alert is generated if any agents have been moved by the rule.
Note:
Any agents that are managed by management servers outside of the configured resource pool are not touched by this rule.
Gateway servers are automatically excluded even when the configured resource pool contains both management servers and gateway servers.
Remove Disabled Discovery Instance
Workflow Name: OpsMgr Self Maintenance Remove Disabled Discovery Objects Rule
These workflows are designed to remove objects that were discovered by already disabled discoveries from the database. For more information, please refer to this blog article: http://blogs.technet.com/b/jonathanalmquist/archive/2008/09/14/remove-disabledmonitoringobject.aspx
The following parameters can be configured via overrides:
IntervalHours: How often does the rule run. By default, every 24 hours.
SyncTime: What time does the rule run. By default, 23:45
TimeoutSeconds: Timeout in seconds for the PowerShell script inside the rule. By default, 3600 seconds.
Management packs Backup
Workflow Name: OpsMgr Self Maintenance Management Packs Backup Rule
These rules run on a schedule and backup management packs that are currently loaded in the management group.
There are many community written MPs for this purpose, the rules from these management packs can be configured to also export (backup) sealed management packs. When they are configured to backup sealed MPs, the sealed MPs are exported to unsealed (XML) MPs.
A critical alert is raised when the backup failed.
I found this option useful sometimes when I wanted to quickly check the content of a sealed MP, all I had to do was to go to the backup destination and open the unsealed XML version using a text editor. It can also be useful when you need to quickly restore an in-house written MP. All you have to do is to grab the unsealed version of the MP from the backup destination and seal it again using your own key.
The following parameters can be configured via overrides:
IntervalSeconds: Schedule frequency in seconds
SyncTime: Time when the rule runs. It’s recommended to configure this rule to rule BEFORE the nightly OS backup for the destination so they are backed up to backup media.
BackupLocation: Backup destination. It can be a local folder or a UNC path. For the version, since this rule will potentially run on any management server in "All Management Servers Resource Pool", please use a UNC path instead of a local path so MPs are backed up to a centralized location.
BackupSealedMP (Boolean): Default value is set to true. Set it to false if sealed management packs do not need to be exported during the backup process.
RetentionDays: Backup file retention. Any backup sets older than the retention period will be deleted.
TimeoutSeconds: Timeout in seconds for the PowerShell script within this rule. The default is 900 seconds (15 minutes). Increase it if it’s required.
Prior to enabling this job, please make sure the backup destination folder exists and the management server’s action account has least Modify NTFS permission and Change Share permission to the destination folder.
Note:
The PowerShell script used by these workflows automatically creates a subfolder under “BackupLocation” with the name of the management group and management packs will be backed up to the sub-folder. In an environment with multiple OpsMgr management groups, administrators can use a single backup location for multiple management groups.
The Management server’s default action account must have write access to the backup location (UNC path).
Covert All Agents to Remote Manageable
Workflow Name: OpsMgr Self Maintenance Convert All Agents To Remote Manageable Rule
These workflows run on a schedule and convert any manually installed OpsMgr agents to “Remote Manageable” by using SQL command “UPDATE MT_HealthService SET IsManuallyInstalled=0 WHERE IsManuallyInstalled=1” against the operational DB.
If any agents have been converted, an information alert is created indicating the number of agents converted. For environments that are fairly static, this rule may not be required (or required to run less often).
The following parameters can be customized via overrides:
IntervalHours: How often the rule is set to run, default is every 12 hours.
SQLQueryTimeoutSeconds: timeout second for the SQL query execution within the PowerShell script. Default is 180 seconds.
SyncTime: time when the rule runs.
TimeoutSeconds: timeout seconds for the PowerShell script used by the rule.
Note:
If both this rule and the balance agents rule are enabled, it’s recommended to schedule this rule to run first, because agents need to be remotely manageable to move to other management servers.
Detect Stale State Change Events in Database
Workflow Name: OpsMgr Self Maintenance Stale State Change Events Detection Rule
This workflow detects if stale state change events exist in the database (event age older than the state change event data grooming setting). This is because state change events created by already disabled monitors are not groomed out by the grooming jobs. A critical alert is raised when the earliest state change event in the database is more than 1 day older than the “State change events data” grooming setting. The SQL command used to delete these events is included in the knowledge article of the rule.
For more information, please refer to this blog article: https://kevinholman.com/2009/12/21/tuning-tip-do-you-have-monitors-constantly-flip-flopping/
The following parameters can be customized using overrides:
DaysOfWeekMask: The day of the week when the rule runs. This rule does not need to run too often, the default is every Sunday. Please refer to the PublicSchedulerType definition http://msdn.microsoft.com/en-us/library/ee692976.aspx if you wish to modify which day(s) this rule should run.
StartTime: Time when the run rules. Default is 3:00am (Sunday)
SQLQueryTimeout: timeout second for the SQL query execution within the PowerShell script. Default is 300 seconds.
TimeoutSeconds: timeout seconds for the PowerShell script used by the rule.
Note:
The table below outlines what the integer value of the “DaysOfWeekMask” represents:
Day | Value |
Sunday | 1 |
Monday | 2 |
Tuesday | 4 |
Wednesday | 8 |
Thursday | 16 |
Friday | 32 |
Saturday | 64 |
To specify a single day, enter the enumerator value for that day directly into the DaysOfWeekMask configuration element.
To specify multiple days, add the enumerator values for the days together. For example, for Monday, Wednesday, and Friday, specify 42 (2+8+32).
Close Old Rule Generated Alerts
Workflow Name: OpsMgr Self Maintenance Close Aged Rule Generated Alerts Rule
This rule close rule generated alerts. The following parameters can be customized via overrides:
CloseCriticalAlerts (Boolean): Whether critical alerts should be closed.
CloseInfoAlerts (Boolean): Whether information alerts should be closed.
CloseWarningAlerts (Boolean): Whether warning alerts should be closed.
DaysToKeep: Alerts maximum age before been closed.
IntervalSeconds: How often in seconds the rule runs. By default, 86400 seconds (1 day).
UseLastModifiedDate: Default value is set to false. Set it to true if you wish to filter alerts using 'LastModified' date rather than 'TimeRaised' date. When set to true, only alerts that have not been updated for the given period will be closed.
Enable Agent Proxy for all agents
Workflow Name: OpsMgr Self Maintenance Enable Agent Proxy Rule
These workflows runs on a schedule and enables Agent Proxy setting for all OpsMgr agents. They use the script posted in this blog article: http://blog.tyang.org/2012/09/06/powershell-script-to-enable-scom-agent-proxy-in-a-more-efficient-way/
The following parameters can be customized via overrides:
IntervalSeconds: How often in seconds the rule runs. By default, 86400 seconds (1 day).
SQLQueryTimeout: timeout second for the SQL query execution within the PowerShell script. The default is 120 seconds.
TimeoutSeconds: timeout seconds for the PowerShell script used by the rule.
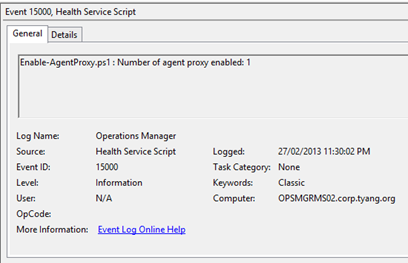
UpdateDefaultSetting: default value is True. When set to true, the rule sets the agent proxy default Management Group setting to True.
The script used in the workflows logs an information event with event ID 15000 in the Operations Manager event log on the management server where it ran from.
Collect Total SDK Client Connections among All Management Servers
Workflow Name: Collect All Management Server SDK Connection Count Rule
This performance collection rule runs on a schedule to collect SDK connection count from each management server in the OpsMgr management group and present the total number of SDK connections as performance data.
The performance data can be access either via any performance reports or performance views in operational console.
Target: All Management Servers Resource Pool
Perf Data Object: OpsMgr SDK Service
Perf Data Counter: Total Client Connections
Checking the size of LocalizedText table in Operational DB
Workflow Name: OpsMgr Self Maintenance Operational Database LocalizedText Table Health Monitor
These monitors detect if the LocalizedText table is the largest table in the Operational database and the row count is above the configured threshold. These monitors run on a schedule (by default once a day), and raises alert if LocalizedText table is the largest table AND the row count is above configured threshold (default threshold is 1,000,000).
For more information in regards to LocalizedText table, please refer to this blog article: https://web.archive.org/web/20150827142734/http://blogs.technet.com/b/kevinholman/archive/2008/10/13/does-your-opsdb-keep-growing-is-your-localizedtext-table-using-all-the-space.aspx
The following parameters can be customized via overrides:
IntervalHours: How often does the monitor run. By default, every 24 hours.
SQLQueryTimeout: timeout second for the SQL query execution within the PowerShell script. Default is 300 seconds.
RowCountThreshold: The row count threshold, default is 1,000,000 (1 million).
SyncTime: time when the monitor runs.
TimeoutSeconds: timeout seconds for the PowerShell script used by the rule.
Agent Task: Enable Agent Proxy For All Agents
This task runs the same write action module as the Enable Agent Proxy For All Agents rule.
Agent Task: Backup Management Packs
This task can be used to manually backup management packs.
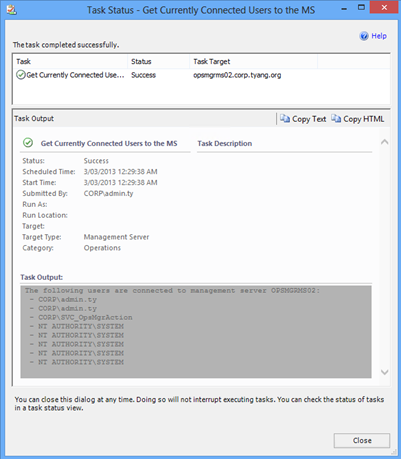
Agent Task: Get Current Connected Users to MG / MS
This task displays the user names who are currently connected to the SDK service on a particular management server.
i.e.
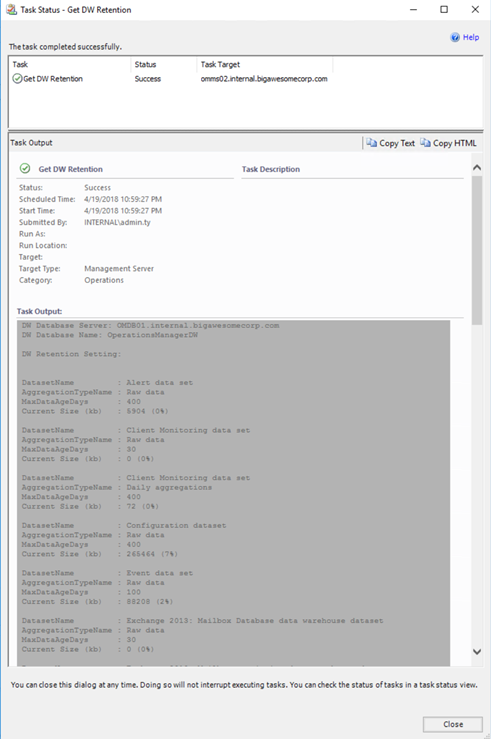
Agent Task: Get DW Retention
This task displays the data retention period for each data warehouse data set:
Detecting User Defined Overrides in the Default Management Pack
The “OpsMgr Self Maintenance Detect User Defined Overrides in Default MP Rule” detects any user-defined overrides that are saved in the Default Management Pack.
This rule targets the “All Management Servers Resource Pool” and it is triggered when an updated Default Management Pack is received by the management group. It then executes a PowerShell script to detect user-defined overrides in the default MP. This rule can be modified using the following override parameters:
MinutesToCheck: used by the PowerShell script, it looks for any user-defined overrides created since x minutes ago. When setting this value to 0, the script will look for ALL user-defined overrides. The default value is 10.
TimeoutSeconds: Defines the number of seconds allowed for the PowerShell script execution. The default value is 120.
An alert is generated when users have saved overrides in the Default Management Pack. This is against the OpsMgr best practice. It will create unnecessary dependencies between the default MP and other MPs, which will cause problems when deleting management packs.
To resolve the issue, firstly, identify and remove the override. Then export the default MP, delete the reference to the source MP and re-import the default MP back to the management group.
Note:
This rule is triggered events in the Operations Manager event log. When all of the following conditions are true:
Event ID = 1201
Event Source = HealthService
The first parameter in the event data =” Microsoft.SystemCenter.OperationsManager.DefaultUser” (the default management pack)
This rule will not alert on the two (2) built-in overrides stored in the Default Management Pack.
For more information in regards to cleaning up the Default Management Pack, please refer to the article below:
https://kevinholman.com/2008/11/11/cleaning-up-the-default-mp/
Collecting the Outstanding Number of Data Sets to be Processed by DW DB Aggregation Processes
The “OpsMgr Self Maintenance Data Warehouse Database Aggregation Process Performance Collection Rule” collects the outstanding count of dataset still to be processed by the DW DB hourly and daily aggregation process. Higher count may indicate there is a performance-related issue with the OpsMgr Data Warehouse Database. This rule is adopted from Michel Kamp's blog post: http://michelkamp.wordpress.com/2013/03/24/get-a-grip-on-the-dwh-aggregations/
The performance data collected by this rule can be viewed in the “Standard Data Set Performance View”:
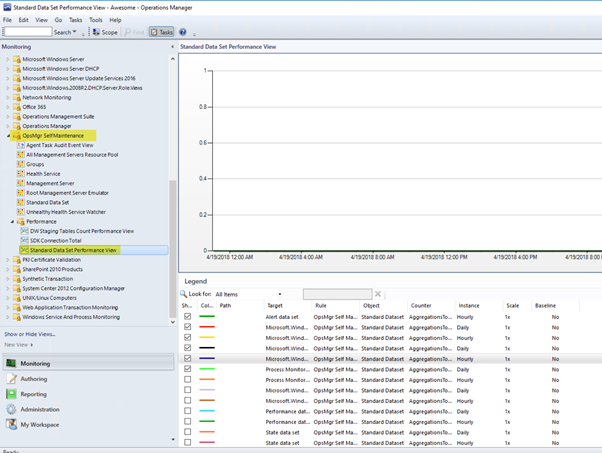
By default, this rule runs hourly against DW standard Data Sets. There are also two (2) separate 3-state monitors from this management pack that would generate alerts when the outstanding data sets are above-configured thresholds.
There are several possible causes for the higher performance reading. More information can be found in this article: http://blogs.technet.com/b/operationsmgr/archive/2011/09/06/standard-dataset-maintenance-troubleshooter-for-system-center-operations-manager-2007.aspx
For additional information in regards to this issue, please refer to the article below: http://michelkamp.wordpress.com/2012/04/10/scom-dwh-aggregations-data-loose-tip-and-tricks/
Configuring Failover Management Servers for Agents within a Resource Pool
The “OpsMgr Self Maintenance Configure Agents Failover within Resource Pool Rule” runs on ALL management servers according to a schedule and configure failover management servers for agents reporting to the management server if the management server is a member of the resource pool as defined via the override. All other management servers that are members of the defined resource pool will be configured as failover management servers for the agents.
This rule can be customized using overrides:
IntervalHours: How often (in hours) does this rule run.
ResourcePoolName: Resource Pool Name.
MaxAgentsToConfig: Maximum number of agents to be configured at a time.
SyncTime: What time does this rule run.
TimeoutSeconds: Timeout in seconds for the PowerShell script inside the rule. Note: in a large management group, this script may take a long time to run.
This rule will configure failover management servers for agents where the number of current failover management servers does not equal the number of the remaining management servers (not including the primary management server) within the resource pool. This script will not make any configuration changes if it is being targeted to a gateway management server or if the targeted management server is not a member of the resource pool.
An information alert is generated if the rule has configured at least one (1) agent(s) on the management server.
Note:
This rule is targeting every management server due to concerns with performance. The script within this workflow checks if the targeted management server is a member of the defined resource pool. It will not continue if the management server is not a member.
The “Balancing agents within resource pool” rule also configures failover management servers for agents when the agents are being moved. However, if the agent has never been moved to another management server by the balancing agents rule, the failover management servers would not be configured. Therefore this rule fills the gap by configuring all required agents.
Monitoring Outstanding DW Data Sets to be aggregated
Workflow Names:
OpsMgr Self Maintenance Check Data Warehouse Database Daily Aggregation 3-State Monitor
OpsMgr Self Maintenance Check Data Warehouse Database Hourly Aggregation 3-State Monitor
These two (2) monitors run on a schedule and check for number of DW standard data sets that are waiting to be aggregated (aggregation type: Hourly and Daily). These two (2) monitors are adopted from Michel Kamp's blog post: http://michelkamp.wordpress.com/2013/03/24/get-a-grip-on-the-dwh-aggregations/
By default, these monitors run hourly and have 2 thresholds. The default warning threshold is configured to 4 and critical threshold is configured to 10.
There are several possible causes for this monitor to become unhealthy. More information can be found from this article: http://blogs.technet.com/b/operationsmgr/archive/2011/09/06/standard-dataset-maintenance-troubleshooter-for-system-center-operations-manager-2007.aspx
The instruction provided from the article below can be used as a guide to rectify the issue:
http://michelkamp.wordpress.com/2012/03/23/dude-where-my-availability-report-data-from-the-scom-dwh/
Additional Information:
http://michelkamp.wordpress.com/2012/04/10/scom-dwh-aggregations-data-loose-tip-and-tricks/
Detect Manually Closed Monitor-Generated Alerts
Workflow Name: OpsMgr Self Maintenance Detect Manually Closed Monitor Alerts Rule
This rule runs on a schedule and detects if any monitor-generated alerts have been closed manually by OpsMgr operators. A warning alert is generated with when manually closed monitor-generated alerts are detected:
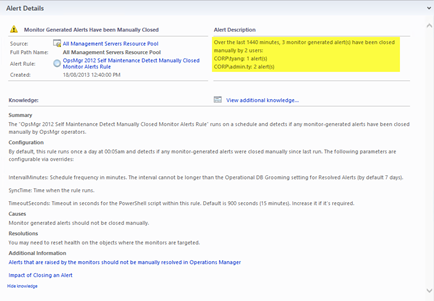
By default, this rule runs once a day at 00:05am and detects if any monitor-generated alerts were closed manually since last run. The following parameters are configurable via overrides:
IntervalMinutes: Schedule frequency in minutes. The interval cannot be longer than the Operational DB Grooming setting for Resolved Alerts (by default 7 days).
SyncTime: Time when the rule runs.
ResetUnitMonitors: When set to 'true', the rule will also reset the health state of the monitor of which generated the alert if the monitor is a unit monitor and its state is warning or error.
TimeoutSeconds: Timeout in seconds for the PowerShell script within this rule. Default is 900 seconds (15 minutes). Increase it if it’s required.
More information regarding to this behavior:
Alerts that are raised by the monitors should not be manually resolved in Operations Manager
Note:
This rule has been updated in Version 2.5, which added an overrideable parameter “ResetUnitMonitors”.
Agent Task: Get Management Groups
This agent task is targeting the “Agent” object in OpsMgr. it displays the management group(s) that are currently configured on the agent.
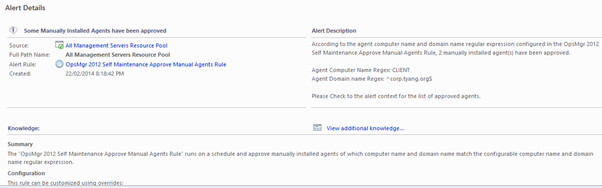
Auto Approve Manually Installed Agents based on Agents computer name and domain name regular expression match
Workflow Name: OpsMgr Self Maintenance Approve Manual Agents Rule
By default in OpsMgr, there are 3 possible options for manually installed agents:
Reject all
Automatically Approve all
Manually Approve by OpsMgr administrators
The “OpsMgr Self Maintenance Approve Manual Agents Rule” runs on a schedule and approve manually installed agents of which computer name and domain name match the configurable computer name and domain name regular expression. This rule presents 2 benefits:
Allow OpsMgr to automatically approve agents based on preconfigured naming convention. It eliminates the needs for administrators to manually approve agents.
Agents approvals are staged. This prevents large number of agents are approved at once. In a large OpsMgr environment, this is particularly important as approving a large number of agents at once could consume a lot of system resources on management servers to transfer management packs and process the initial discovery workflows submitted from the agents.
This rule can be customized using overrides:
IntervalMinutes: How often (in minutes) does this rule run.
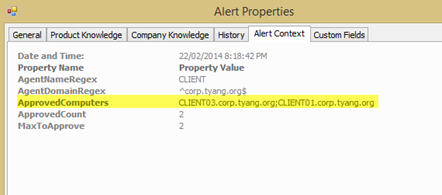
AgentNameRegex: Regular Expression for acceptable Agent computer names
AgentDomainRegex: Regular Expression for acceptable Agent domain names
MaxToApprove: Maximum number of manually installed agents to be approved at a time.
SyncTime: What time does this rule run.
TimeoutSeconds: Timeout in seconds for the PowerShell script inside the rule.
This rule will approve manually installed agents (up to the number configured for MaxToAPprove) if both agent's computer name and domain name match configured regular expressions.
An information alert is generated if the rule has approved at least one (1) agent(s).
The list of approved agents is available in Alert Context:
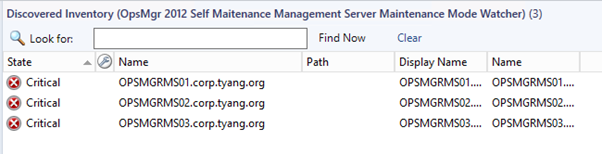
Detect if each individual management server is in maintenance mode
Workflow Names:
OpsMgr Self Maintenance Management Server Maintenance Mode Watcher Discovery
OpsMgr Self Maintenance Local Management Server in Maintenance Mode Monitor
OpsMgr Self Maintenance Local Management Server In Maintenance Mode Monitor Recovery Task
This rule runs on a separate unhosted class called “OpsMgr Self Maintenance Management Server Maintenance Mode Watcher” is created for the management servers.
This class is discovered on each OpsMgr management server but it is not hosted by Windows Computer. I have taken this idea from Kevin Holman’s blog article How to create workflows that won't go into Maintenance Mode. By doing so, the monitor that’s targeting this class will still run even when the management server’s Windows Computer object has been placed into maintenance mode.
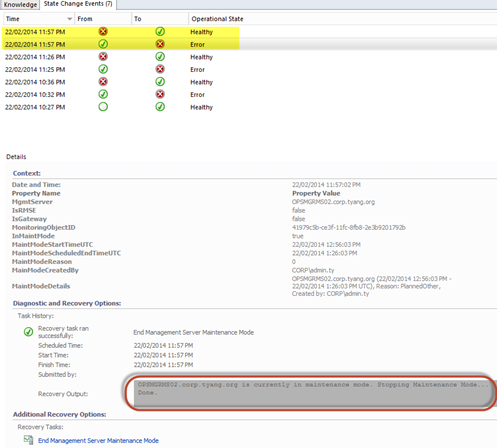
A recovery task is also associated with this monitor (disabled by default). When enabled, it will automatically end the maintenance mode for the management server.
Note:
Please enable this recovery task with caution. i.e. If the monitor is configured to run every 5 minutes, you will never be able to place a management server into maintenance mode for more than 5 minutes. It may not always be desired.
In order to use this monitor, the following workflows need to be enabled via overrides:
OpsMgr Self Maintenance Management Server Maintenance Mode Watcher Discovery
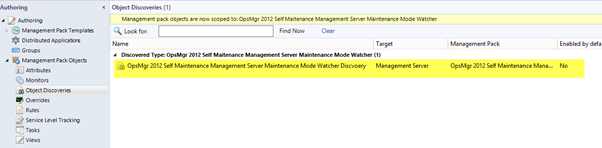
OpsMgr Self Maintenance Local Management Server in Maintenance Mode Monitor
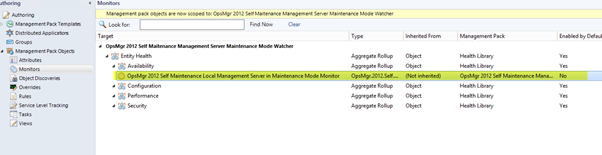
OpsMgr.Self.Maintenance.Local.Management.Server.In.Maintenance.Mode.Monitor.Recovery.Task (Optional)

When the object is enabled, a Maintenance Mode Watcher object will be created for each management server:
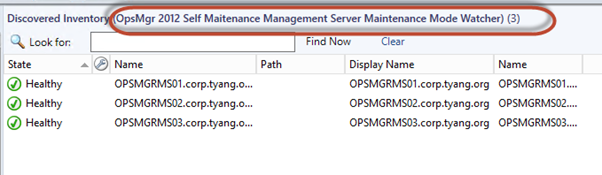
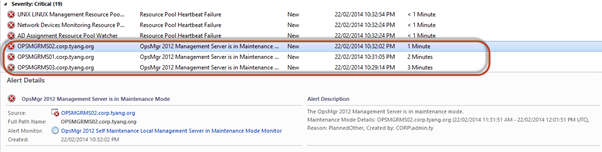
When the monitor is enabled, and management servers are placed into maintenance mode, The health state for the Maintenance Mode Watcher object becomes unhealthy and alerts are generated:
Management servers in Maintenance Mode:
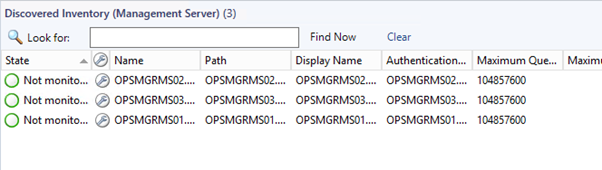
Maintenance Mode Watcher Objects:
Alert for each management server:
If the recovery task is enabled, the management server will automatically be taken out of maintenance mode:
Detect if Management Server Default Action Account has OpsMgr administrator privilege
Workflow Name: OpsMgr Self Maintenance Management Server Default Action Account OpsMgr Admin Privilege Monitor
This monitor targets All Management Servers Resource Pool and runs once a day by default. It checks if the management server’s default action account has OpsMgr administrator privilege within the management group. All workflows within this management pack runs under the default action account. This monitor ensures this account has required privilege within the management group to carry out the administrative workflows within this management pack.
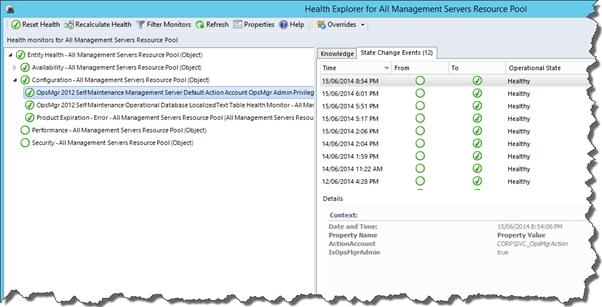
When the monitor detects the Management Server’s default action account does not have OpsMgr administrator privilege, a critical alert will be raised.
Note: On-Demand detection feature has been enabled for this monitor, OpsMgr operators may use the “Recalculate Health” button in Health Explorer to manually trigger the monitor.
The following parameters are configurable via overrides:
IntervalHours: Schedule frequency in hours.
SyncTime: Time when the rule runs.
TimeoutSeconds: Timeout in seconds for the PowerShell script within this rule. Default is 120 seconds (2 minutes). Increase it if it’s required.
Detect if Management Server Default Action Account has local administrator privilege on management servers
Workflow Name: OpsMgr Self Maintenance Management Server Default Action Account Local Admin Privilege Monitor
This monitor targets each management server and runs once a day by default. It checks if the management server’s default action account has local administrator privilege on the management servers. All workflows within this management pack runs under the default action account. This monitor ensures this account has required privilege on the management server to carry out the administrative workflows within this management pack.
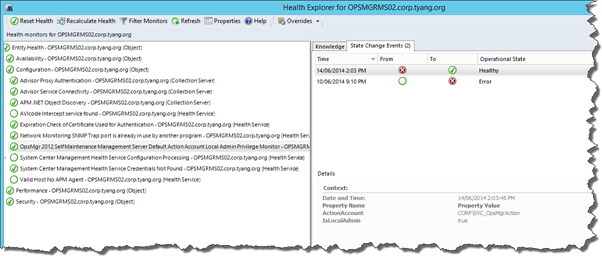
When the monitor detects the Management Server’s default action account does not have local administrator privilege, a critical alert will be raised.
Note: On-Demand detection feature has been enabled for this monitor, OpsMgr operators may use the “Recalculate Health” button in Health Explorer to manually trigger the monitor.
The following parameters are configurable via overrides:
IntervalHours: Schedule frequency in hours.
SyncTime: Time when the rule runs.
TimeoutSeconds: Timeout in seconds for the PowerShell script within this rule. The default is 120 seconds (2 minutes). Increase it if it’s required.
Detect Obsolete Management Pack References (MP Aliases) in Unsealed Management Packs
Workflow Name: OpsMgr Self Maintenance Obsolete Management Pack Alias Detection Rule
This rule runs on a schedule and detects obsolete aliases from unsealed management packs. These obsolete references create unnecessary dependencies between management packs. It prevents sealed management packs from deletion.
When references to the following built-in common management packs are detected in any unsealed management packs, they will be ignored (the whitelist):
Microsoft.SystemCenter.Library
Microsoft.Windows.Library
System.Health.Library
System.Library
Microsoft.SystemCenter.DataWarehouse.Internal
Microsoft.SystemCenter.Notifications.Library
Microsoft.SystemCenter.DataWarehouse.Library
Microsoft.SystemCenter.OperationsManager.Library
System.ApplicationLog.Library
Microsoft.SystemCenter.Advisor.Internal
Microsoft.IntelligencePacks.Types
Microsoft.SystemCenter.Visualization.Configuration.Library
Microsoft.SystemCenter.Image.Library
Microsoft.SystemCenter.Visualization.ServiceLevelComponents
Microsoft.SystemCenter.NetworkDevice.Library
Microsoft.SystemCenter.InstanceGroup.Library
Microsoft.Windows.Client.Library
Microsoft.IntelligencePacks.CloudUpload
Microsoft.SystemCenter.Advisor
Microsoft.IntelligencePacks.Performance
Microsoft.IntelligencePacks.Dns
Microsoft.IntelligencePacks.SecurityBaselineScom
Microsoft.IntelligencePacks.InventoryChangeTracking
This is because these common management packs are referenced in some out-of-box unsealed management packs by default. Additionally, since it is very unlikely that the above-listed management packs will ever be deleted from the management group, therefore it should not be an issue when they are referenced in other management packs. This rule also allows OpsMgr administrators to add up to 5 additional sealed management packs to the list by utilizing “CustomMP1” – “CustomMP5” override fields (additional items for the whitelist).
This rule can be customized using overrides:
IntervalHours: How often (in hours) does this rule run.
SyncTime: What time does this rule run?
CommonMP1 - CommonMP5: Additional commonly referenced sealed management packs this rule should ignore (the whitelist). When using these overrides, please use the management pack name (ID) instead of the display name.
TimeoutSeconds: Timeout in seconds for the PowerShell script inside the rule.
Alert Suppression: In order to reduce the number of alerts, alert suppression is enabled. The repeat count would increase if same obsolete references are detected. A new alert will only be generated if different obsolete references are detected.
If obsolete MP references are detected, you may remove these obsolete references by using the "Remove Obsolete MP References" (Refer to “Agent Task: Reset Monitor Health State” section below) agent task targeting "All Management Servers Resource Pool".
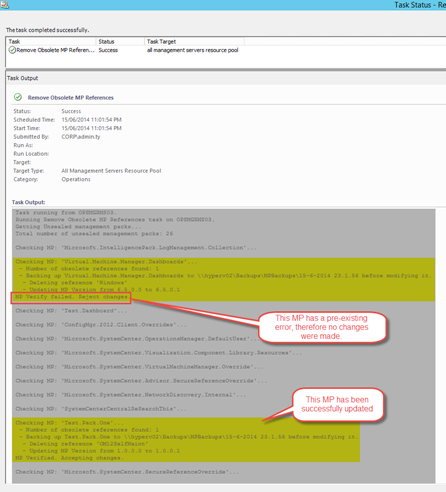
Agent Task: Remove Obsolete MP References
This task is targeting All Management Servers Resource Pool. It is designed to remove obsolete management pack references from unsealed management packs.
Same as the “OpsMgr Self Maintenance Obsolete Management Pack Alias Detection Rule”, the built-in common management packs listed in section 5.2.26 will also be ignored by this task.
When running this task, users must use overrides to define options:
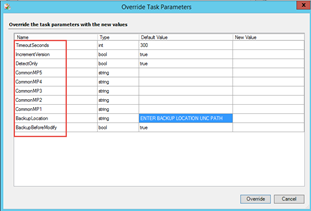
TimeoutSeconds: Timeout in seconds for the PowerShell script used by the task
IncrementVersion: Whether the unsealed MP version should be increased (the last section or the revision number of the MP version will be increased by 1. i.e. MP version 1.0.0.0 would be changed to 1.0.0.1.)
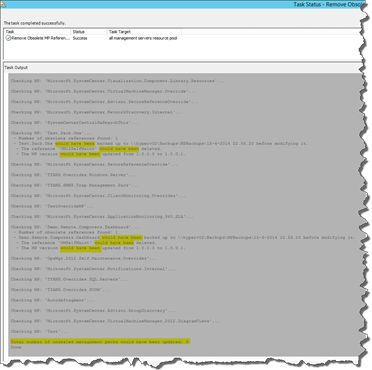
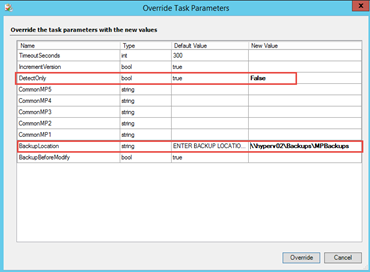
DetectOnly: by default, the value is set to true, which means this task will ONLY detect obsolete references but will NOT delete them. The override MUST be set to false in order to delete obsolete references. This is to prevent accidental updates of the unsealed management pack when the task is executed by accident. It is recommended to run this task using the DetectOnly switch (set to true) first before actually deleting the obsolete references (set to false).
CommonMP1 – CommonMP5: Same as the “OpsMgr Self Maintenance Obsolete Management Pack Alias Detection Rule”, users can define up to 5 additional common MPs to be ignored when running this task. If these overrides are defined in the “OpsMgr Self Maintenance Obsolete Management Pack Alias Detection Rule”, they should also be defined here when running the task.
BackupBeforeModify: Specify whether the task should backup each unsealed management packs before modification if it needs to be updated. When this is set to true (by default), the BackupLocation override should also be specified.
BackupLocation: Specify a location where the unsealed management packs will be updated. Because the task is targeting a resource pool, it is recommended to use an UNC path instead of a local path. The task will create a sub-folder that is named as the current timestamp in this location and the MPs will be backed up in this subfolder.
Note: When configured the task to remove the obsolete references, the script used by this task verifies the MP before committing changes. If there are any errors found, including pre-existing errors, the changes will NOT be committed and the MP will not be updated.
i.e. Running the task using DetectOnly switch:
i.e. Running the task with DetectOnly set to false:
Agent Task: Get Workflow Name (ID)
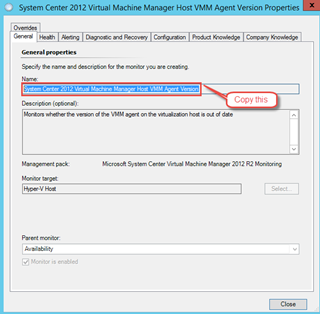
This task is targeting All Management Servers Resource Pool. It is designed to display the name (sometimes also refers to ID) of a rule, monitor, or discovery workflow. This would help administrators to easily retrieve the real name of a workflow because users can only see the display names in the Operations console.
To use this task, firstly copy the display name of the workflow (rule / monitor / discovery) in Operations Console,
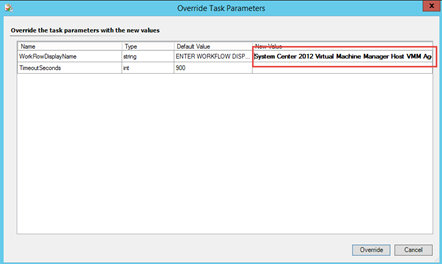
Then enter or paste the display name in the override field of this task:
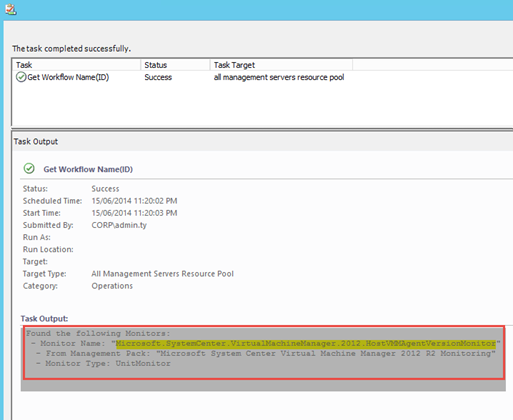
All workflows with such display name will be displayed in the output pane when the task is executed:
Agent Task: Reset Monitor Health State
This task is targeting All Management Servers Resource Pool. It is designed to reset the health state of a particular monitor on all unhealthy monitoring objects.
The monitor name (Not display name) must be specified via override. The monitor name can be retrieved using the “Get Workflow Name(ID)” task (refer to the section “Monitoring the Data Warehouse Staging Tables Row Count” below).
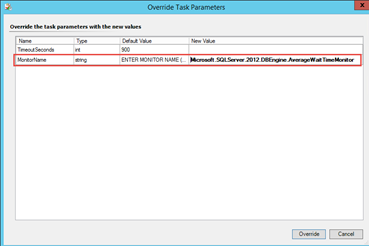
The task result indicates which unhealthy instances have been reset:

Monitoring the Data Warehouse Staging Tables Row Count
The management pack provides few workflows to monitor the following 5 staging tables in the OpsMgr Data Warehouse database:
Alert Staging Table: Alert.AlertStage
Event Staging Table: Event.EventStage
Performance Staging Table: Perf.PerformanceStage
State Staging Table: State.StateStage
Managed Entity Staging Table: ManagedEntityStage
Higher row count on these tables may indicate performance-related issues on the OpsMgr Data Warehouse DB and SQL server. The OpsMgr Self Maintenance MP provides a performance collection rule and a 2-state performance threshold monitor for each of these 5 tables:
Performance Collection Rules:
OpsMgr Self Maintenance Data Warehouse Database Alert Staging Table Row Count Performance Collection Rule
OpsMgr Self Maintenance Data Warehouse Database Event Staging Table Row Count Performance Collection Rule
OpsMgr Self Maintenance Data Warehouse Database ManagedEntity Staging Table Row Count Performance Collection Rule
OpsMgr Self Maintenance Data Warehouse Database Performance Staging Table Row Count Performance Collection Rule
OpsMgr Self Maintenance Data Warehouse Database State Staging Table Row Count Performance Collection Rule
2-State Performance Monitors:
OpsMgr Self Maintenance Data Warehouse Database Alert Staging Table Row Count 2 State Threshold Monitor
OpsMgr Self Maintenance Data Warehouse Database Event Staging Table Row Count 2 State Threshold Monitor
OpsMgr Self Maintenance Data Warehouse Database Managed Entity Staging Table Row Count 2 State Threshold Monitor
OpsMgr Self Maintenance Data Warehouse Database Performance Staging Table Row Count 2 State Threshold Monitor
OpsMgr Self Maintenance Data Warehouse Database State Staging Table Row Count 2 State Threshold Monitor
All of the above-listed rules and monitors are targeting the “All Management Servers Resource Pool” and they are disabled by default. In order to utilize the OpsMgr Cook Down feature, these rules and monitors are sharing the same data source module with the same input parameters. Therefore, when modifying the input parameters for these workflows, please make sure the same override is applied to all of the above-mentioned rules and monitors otherwise it will break Cook Down.
Monitoring the Patch Level of Various OpsMgr Components
When applying OpsMgr Update Rollups (UR), a certain order must be followed. Failed to do so may lead to the inconsistent UR among various components. In order to address this common problem, the OpsMgr Self Maintenance MP has provided the following workflows:
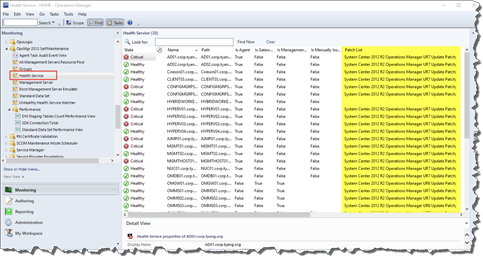
State view for Health Service which also displays the patch list:
An agent task targeting Health Service to list OpsMgr components patch level:
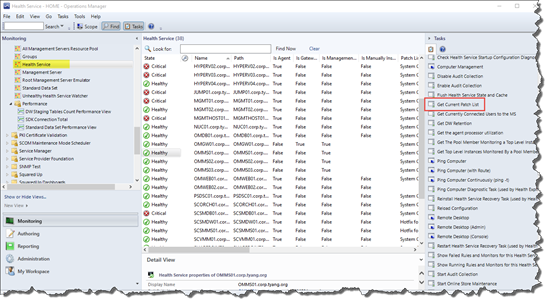
This task will display the patch list for any of the following OpsMgr components installed on the selected health service:
Management Servers | Gateway Servers |
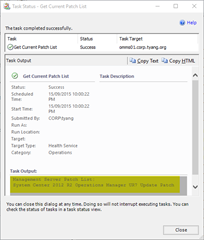 | 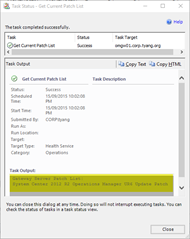 |
Agent | Web Console (Also an agent) |
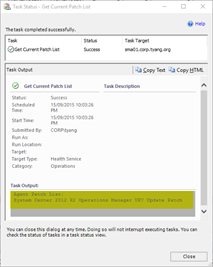 | 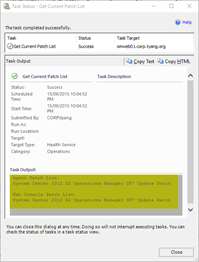 |
Object Discovery: OpsMgr Self Maintenance Management Server and Agent Patch List Discovery
Natively in OpsMgr, the agent patch list is discovered by an object discovery called “Discovers the list of patches installed on Agents”:
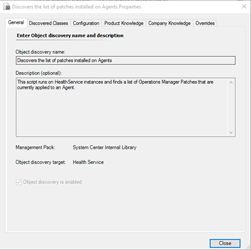
As the name suggests, this discovery discovers the patch list for agents, and nothing else. It does not discover the patch list for OpsMgr management servers, gateway servers, and SCSM management servers (if they are also monitored by OpsMgr using the version of the Microsoft Monitoring Agent that is a part of the Service Manager). The discovery provided by the OpsMgr Self Maintenance MP is designed to replace the native patch list discovery. Instead of only discovering the agent patch list, it also discovers the patch list for OpsMgr management servers, gateway servers, SCSM management servers, and SCSM Data Warehouse management servers.
Same as all other workflows in the Self Maintenance MP, this discovery is disabled by default. In order to start using this discovery, please disable the built-in discovery “Discovers the list of patches installed on Agents” BEFORE enabling “OpsMgr Self Maintenance Management Server and Agent Patch List Discovery”:
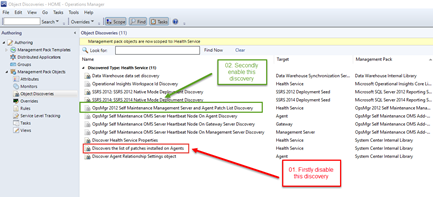
Shortly after the built-in discovery has been disabled and the “OpsMgr Self Maintenance Management Server and Agent Patch List Discovery” has been enabled for the Health Service class, the patch list for the OpsMgr management servers, gateway servers and SCSM management servers (including Data Warehouse management server) will be populated (as shown in the screenshot below):
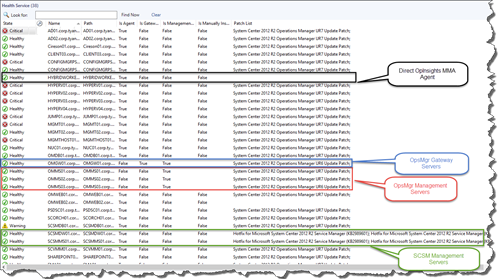
Note:
As shown above, the patch list for different flavors of Health Service is properly populated, with the exception of the Direct Microsoft Monitoring Agent for OpInsights (OMS). This is because, at the time of writing this documentation, Microsoft has yet released any patches to the OMS direct MMA agent. The last Update Rollup for the Direct MMA agent is actually released as an updated agent (MSI) instead of an update (MSP). Therefore, since there is no update to the agent installer, the patch list is not populated.
Warning:
Please do not leave both discoveries enabled at the same time as it will cause config-churn in your OpsMgr environment.
Monitor: OpsMgr Self Maintenance All Management Servers Patch List Consistency Consecutive Samples Monitor
This consecutive sample monitor is targeting the “All Management Servers Resource Pool” and it is configured to run every 2 hours (7200 seconds) by default. It executes a PowerShell script that uses WinRM to remotely connect to each management server and check if all the management servers are on the same UR patch level.
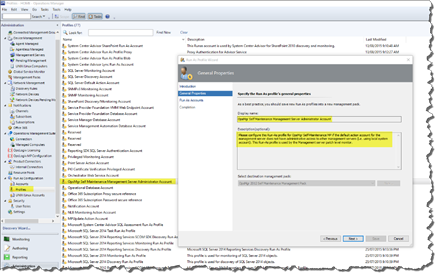
In order to utilize this monitor, WinRM must be enabled and configured to accept connections from other management servers. The quickest way to do so is to run “Winrm QuickConfig” on these servers. The account that is running the script in the monitor must also have OS administrator privilege on all management servers (by default, it is running under the management server’s default action account). If the default action account does not have Windows OS administrator privilege on all management servers, a Run-As profile can be configured for this monitor:
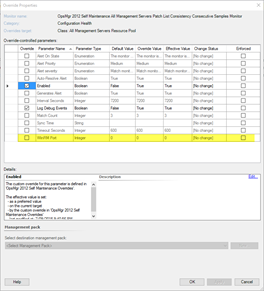
In addition to the optional Run-As profile, if WinRM on management servers are listening to a non-default port, the port number can also be modified via override:
Note:
All management servers must be configured to use the same WinRM port. Using different WinRM port is not supported by the script used by the monitor.
If the monitor detected inconsistent patch level among management servers in 3 consecutive samples, a Critical alert will be raised:
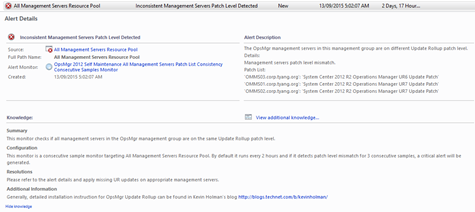
The number of consecutive samples can be modified by overriding the (Match Count) parameter.
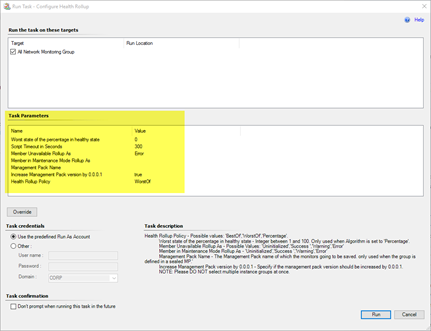
Agent Task: Configure Health Rollup (Configure Group Health Rollup)
In OpsMgr, groups are frequently used when designing service level monitoring and dashboards. The group members’ health rollup behaviors can be configured by creating various dependency monitors targeting against the group.
When creating groups, only instance groups can be created within the OpsMgr console. Unlike computer groups, instance groups do not inherit any dependent monitors from their base class. Therefore when an instance group is created in the OpsMgr console, by default, the health state of the group is “Not monitored” (Uninitialized):
In order to configure group members to rollup health state to the group object (so the group can be used in dashboards), one or more dependency monitors must be created manually after the group has been created. This manual process can be time-consuming. This agent task is created to simplify the process of configuring groups’ health rollup by creating a set of dependency monitors using OpsMgr SDK.
Although a set of required parameters are pre-configured for the agent task, the operators can also modify these parameters using overrides.
The following parameters can be customized via overrides:
Health Rollup Policy: Possible values: ‘BestOf’, ‘WorstOf’, ‘Percentage’
Worst state of the percentage in healthy state: Integer between 1 and 100. Only used when Algorithm is set to ‘Percentage’
Member Unavailable Rollup As: Possible Values: ‘Uninitialized’, ‘Success ‘, ‘Warning’ and ‘Error’
Member in Maintenance Mode Rollup As: ‘Uninitialized’, ‘Success’, ‘Warning’ and ‘Error’
Management Pack Name: The Management Pack name of which the monitors going to be saved. Only used when the group is defined in a sealed MP.
Increase Management Pack version by 0.0.0.1: Specify if the management pack version should be increased by 0.0.0.1.
NOTE: Please DO NOT select multiple instance groups at once.
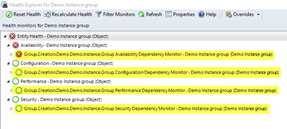
After the task is executed against a group, 4 dependency monitors are created:
Availability Dependency Monitor
Configuration Dependency Monitor
Performance Dependency Monitor
Security Dependency Monitor
Security Consideration
Natively in OpsMgr, only user accounts assigned either authors role or administrators role have access to create monitors. However, users with lower privileges (such as operators and advanced operators) can potentially execute this task and create dependency monitors.
Please keep this in mind when deploying this management pack. You may need to scope user roles accordingly to only allow appropriate users to have access to this task.
This agent task has previously published via a separate management pack: http://blog.tyang.org/2015/07/28/opsmgr-group-health-rollup-configuration-task-management-pack/.
From version 2.5, it has been made as part of the Self Maintenance MP.
Audit Agent Task Execution Results
In OpsMgr, the task history is stored in the Operational DB, which has a relatively short retention period:
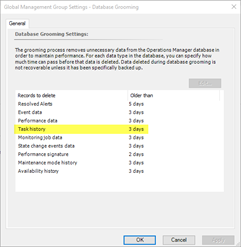
The “OpsMgr Self Maintenance Audit Agent Tasks Result Event Collection Rule” is designed to collect the agent task execution result and store it in both operational and Data Warehouse DB as event data. Because the data in the DW database generally has a much longer retention, the task execution results can be audited and reported.
Once enabled, this rule runs every 5 minutes by default. It retrieves all the task execution results since last rule execution using OpsMgr SDK and format each agent task execution result as an event before saving it to both operational and data warehouse DB. The event severity is Information and the event ID is 102. This management pack also provides an event view for event data collected by this rule:
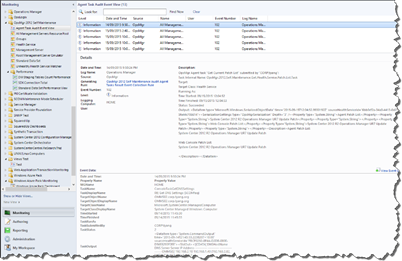
Note:
This rule was inspired by this blog post (although the script used in this rule is completely different than the script from this post): http://www.systemcentercentral.com/archiving-scom-console-task-status-history-to-the-data-warehouse/
Detect OpsMgr Evaluation License Is In Use
When an OpsMgr management group is firstly installed, it is running on an evaluation license. An OpsMgr administrator must manually install a valid license key using the OperationsManager PowerShell module before the evaluation end date. If a valid license key is not installed before then, the management group will stop functioning. At that stage, you may find it is very difficult to install a license key.
Once enabled, the “OpsMgr Self Maintenance Check License Status Alerts Rule” Runs once a day by default, and alert when a valid license is not installed.
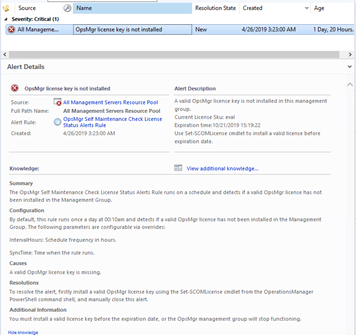
You can modify the frequency and time this rule runs via overrides.